Publications
* indicates equal contribution
ZeroVO: Visual Odometry with Minimal Assumptions
Lei Lai*, Zekai Yin*, Eshed Ohn-Bar
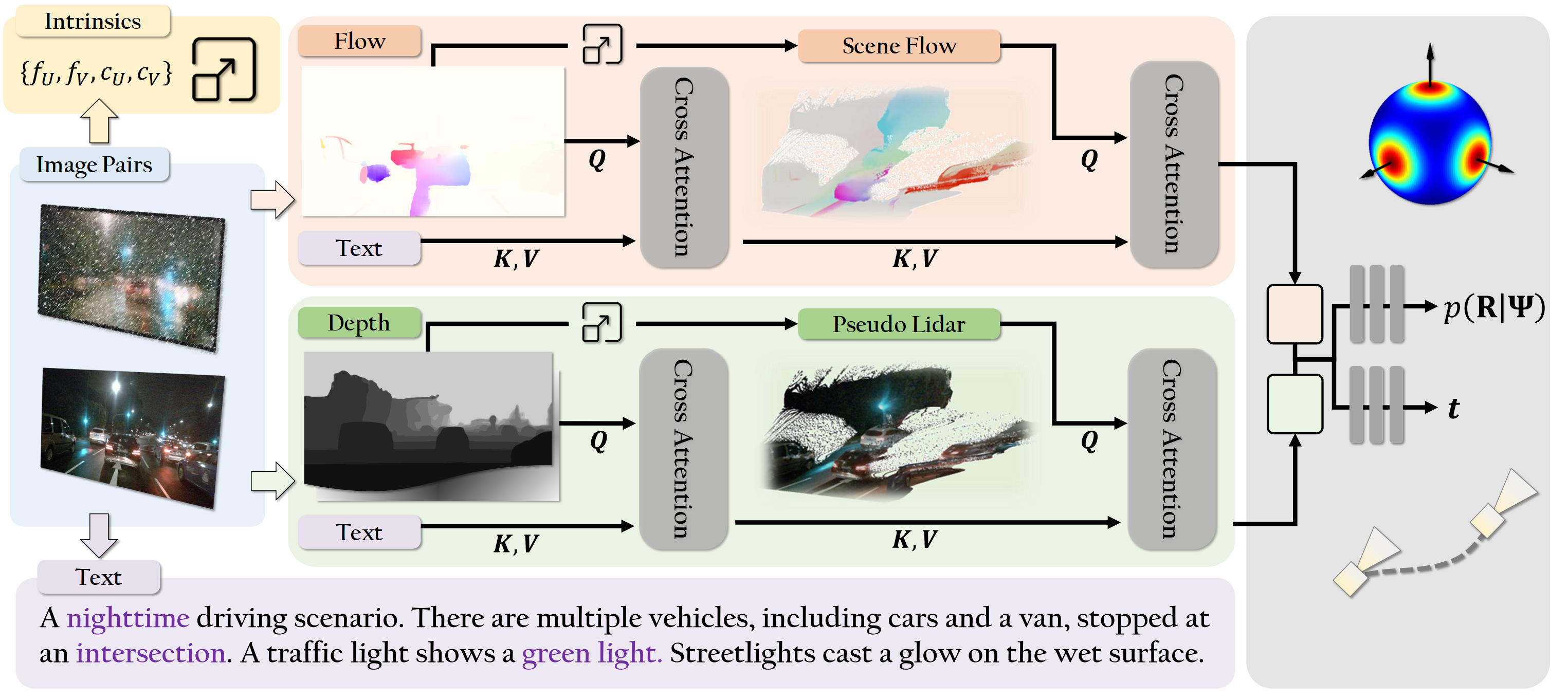
We introduce ZeroVO, a novel visual odometry (VO) algorithm that achieves zero-shot generalization across diverse cameras and environments, overcoming limitations in existing methods that depend on predefined or static camera calibration setups. Our approach incorporates three main innovations. First, we design a calibration-free, geometry-aware network structure capable of handling noise in estimated depth and camera parameters. Second, we introduce a language-based prior that infuses semantic information to enhance robust feature extraction and generalization to previously unseen domains. Third, we develop a flexible, semi-supervised training paradigm that iteratively adapts to new scenes using unlabeled data, further boosting the models’ ability to generalize across diverse real-world scenarios. We analyze complex autonomous driving contexts, demonstrating over 30% improvement against prior methods on three standard benchmarks—KITTI, nuScenes, and Argoverse 2—as well as a newly introduced, high-fidelity synthetic dataset derived from Grand Theft Auto (GTA). By not requiring fine-tuning or camera calibration, our work broadens the applicability of VO, providing a versatile solution for real-world deployment at scale.
Robot Structure Prior Guided Temporal Attention for Camera-to-Robot Pose Estimation
Yang Tian*, Jiyao Zhang*, Zekai Yin*, Hao Dong
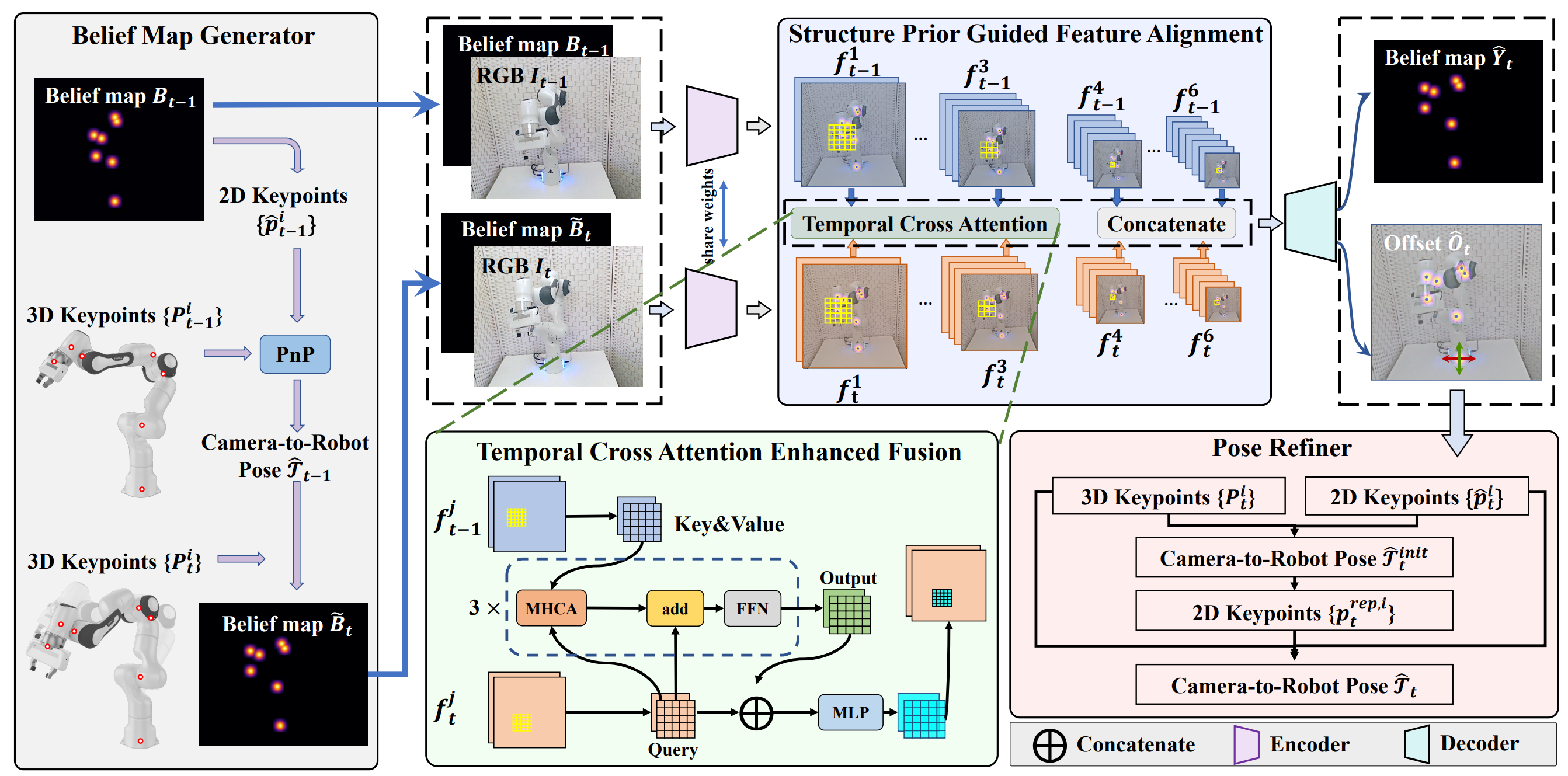
In this work, we tackle the problem of online camera-torobot pose estimation from single-view successive frames of an image sequence, a crucial task for robots to interact with the world. The primary obstacles of this task are the robot’s self-occlusions and the ambiguity of single-view images. This work demonstrates, for the first time, the effectiveness of temporal information and the robot structure prior in addressing these challenges. Given the successive frames and the robot joint configuration, our method learns to accurately regress the 2D coordinates of the predefined robot’s keypoints (e.g. joints). With the camera intrinsic and robotic joints status known, we get the camerato-robot pose using a Perspective-n-point (PnP) solver. We further improve the camera-to-robot pose iteratively using the robot structure prior. To train the whole pipeline, we build a large-scale synthetic dataset generated with domain randomisation to bridge the sim-to-real gap. The extensive experiments on synthetic and real-world datasets and the downstream robotic grasping task demonstrate that our method achieves new state-of-the-art performances and outperforms traditional hand-eye calibration algorithms in real-time (36 FPS).
Research Experience
H2X Lab
Boston University
January 2024 - Present
- Proposed ZeroVO (Zero-Shot Visual Odometry) as a co-first author, presenting a novel visual odometry algorithm with the minimum assumption: only two images without knowing the camera intrinsics. Achieves zero-shot generalization across diverse cameras and environments, overcoming limitations tied to specific sensors and environments. This paper was accepted by IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2025).
- Fused the real-scale world text and geometric information with correspondence features, achieving lower translation and rotation error than the former methods without further alignment.
- Investigated the influence of high-generalizability descriptive insights of the scene derived from Vision-Language Models, pseudo-lidar generated from metric depth, and optical flow-guided-scene flow on the visual odometry task.
- Collected a dataset using Grand Theft Auto with 600 on-road and 600 off-road driving videos (300,000 images) in various driving conditions (speed, weather, driving style, camera parameters, etc.).
- Proposed a Gaussian Mixture Model (GMM)-based diffusion model designed to explicitly capture human-like, multimodal driving decisions in diverse contexts. Achieving state-of-the-art performance on current benchmarks, and reveals weaknesses in standard evaluation practices.
- Developed a human-in-the-loop simulation benchmark with an improved IDM-based reactive driving simulation combining Virtual-Reality and Racing-Game Wheel pads. Reconstructed the validation set of the nuScenes dataset using nerf-based methods (Nerfacto) and Gaussian-splatting-based models (OmniRE, HugSIM) and conducted user studies on it. Collected over 20,000 feasible and diverse driving trajectories.
- Helped collect action data from visually impaired people and their guide dogs using the XSense motion capture system, enriching the diversity of the navigation dataset for real-world applications. Made 3D visualizations with animation using Python-controlled Blender.
- Integrated the Viper X300S robotic arm into a Visual-Language-Action manipulation model pipeline using ROS2 and Python, collected real-world data to fine-tune the model, and conducted real-world experiments.
PKU-Agibot Lab
Peking University
July 2022 - May 2023
- Proposed SGTAPose (Structure-Guided-Temporal-Attention Pose) as a co-first author, tackled camera-to-robot pose estimation from single-view successive frames of an image sequence using temporal cross-attention to estimate camera-to-robot pose in real-time, and achieved a higher precision than traditional hand-eye calibration. This paper was accepted by IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2023).
- Developed the first synthetic video dataset for camera-to-robot pose estimation using Blender (180,000 images).
- Used Ros, Libfranka, Pybullet, Franka-Control, and Ctype to improve the control and motion planning system for the Franka Panda Emika robotic arm to conduct real-world experiments.
- Designed the Refiner module, used the Levenberg-Marquart algorithm to refine the PNP solver by adding a weight to each point according to its reprojection error.
- Combined SAM (Segment Anything Model) and 6D pose estimation model and created a pipeline for the Xarm6 robotic arm for stacking objects, pouring water, and handover objects.
Education
Master of Science in Artificial Intelligence
Boston University
Sep 2023 - Jan 2025
Advisor: Eshed Ohn-Bar
Bachelor of Science in Data Science and Big Data Technology
Peking University
Sep 2019 - Jul 2023
Advisor: Hao Dong
Core Competencies
Languages & Frameworks
Python, C++, C, MATLAB, PyTorch, TensorFlow, Scikit-learn, JAX, Keras, HuggingFace
ML Engineering
MLflow, Weights & Biases, Docker, Kubernetes, ONNX, TensorRT, Ray
Data Processing
NumPy, Pandas, Matplotlib, SciPy, Dask, Spark, Luigi
Computer Vision
OpenCV, Detectron2, YOLO, SAM, NeRF, 3D Reconstruction, Gaussian Splatting, Pose Estimation
Robotics, Simulation & Mechanics
ROS, ROS2, Blender, PyBullet, Libfranka, Franka-Control, CAD, Fusion 360, 3D Printing, Carpentry
Work Experience
Machine Learning Engineer Intern
Nanjing Zealen Technology
Feb 2023 - May 2023
- Designed time-series forecasting models using ST-GCN and PyTorch for 24-hour wind power prediction.
- Implemented Temporal Fusion Transformer and XGBoost models for long-term pollution trend prediction tasks.
- Created feature engineering pipeline processing meteorological data, improving model accuracy by 18% over baselines.
- Developed ML pipeline with MLflow tracking, optimizing hyperparameters through Bayesian optimization techniques.
Software Development Intern
Beijing Siling Robot Technology
Jan 2021 - Feb 2021
- Developed interaction interfaces and API components using C++ and QT for robotic control systems.
- Created cross-platform communication protocols for the robot operating system with low-latency performance requirements.
- Implemented real-time data processing modules for sensor fusion, optimizing robot arm control response times
- Assisted with system integration testing, achieving 99% reliability in production deployment environments.
Leadership & Initiatives
Tutor and Course Organizer
Yuanpei College, Peking University
Mar 2020 - Jul 2023
- Founded carpentry course, developing curriculum and safety protocols.
- Instructed 150+ students; won 2022 YuanPei Special Contribution Award.
Founder and Leader
Yuanpei College 3D Printing and Designing Lab
Feb 2023 - Jul 2023
- Established college's first 3D printing lab with CAD-to-fabrication workflow.
- Designed graduation gifts using parametric modeling and additive manufacturing.